
We investigate using a local large language model (LLM) to replace Github Copilot. We’ll use the StarCoder2 model from HuggingFace, as it is quite new and shows great promise, and we’ll host it with ollama, which just a few hours ago announced support for StarCoder2. Then we point VSCode to ollama + StarCoder2 using the Continue VSCode extension.
Ollama
We start by downloading ollama.
wget https://github.com/ollama/ollama/releases/download/v0.1.28/ollama-linux-amd64
chmod +x ollama-linux-amd64
./ollama-linux-amd64
I tried LMStudio before, but they don’t support StarCoder2 yet, and it has a known issue with older versions of Ubuntu. Ollama does support StarCoder2 as of a few hours ago:
StarCoder2
StarCoder2 was released just a few days ago, so I’m pretty curious to try it out:
Introducing StarCoder 2 ⭐️ The most complete open Code-LLM 🤖 StarCoder 2 is the next iteration for StarCoder and comes in 3 sizes, trained 600+ programming languages on over 4 Trillion tokens on Stack v2. It outperforms StarCoder 1 by margin and has the best overall performance… pic.twitter.com/LVclRcq5ZM
— Philipp Schmid (@_philschmid) February 28, 2024
From the paper, it seems like StarCoder2 performs really well:
We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages.
More specifically:
- StarCoder2-3B is the best in the 3B class of current 3B base models
- StarCoder2-7B comes in second place only behind DeepSeekCoder-6.7B
- StarCoder2-15B is the best in the 15B class of current 15B base models by a significant margin, and is even competitive with models that are more than twice its size, like CodeLlama-34B
However, some models perform better on some programming languages, so it might be worth consulting tables 10 to 12 in the paper to see which model is best for your use case. But for the team at PDFCrunch, Python is crucial, so we consult section 7.1.3 that discusses the models’ performance on Python data science tasks (using the DS-1000 benchmark):
- StarCoder2-3B overall is the best-performing small model on DS-1000. Except for PyTorch and TensorFlow (where it is slightly worse than StableCode-3B), StarCoder2-3B achieves the best performance on all the other popular libraries.
- StarCoder2-7B comes in second place out of the medium models, with a performance similar to DeepSeekCoder-6.7B.
- StarCoder2-15B is the best-performing large model on DS-1000. It substantially outperforms both StarCoderBase-15B and CodeLlama-13B by large margins, and approaches the overall performance of CodeLlama-34B.
Which size model to use?
Which size model you select depends on your GPU’s VRAM. The token length of the code you want to prompt with and generate would normally also be a consideration, but all model sizes have a 16K context window, using a sliding window of 4K, with FlashAttention-2, and as the models don’t use the default self-attention algorithm, large input contexts won’t exhaust your VRAM.
From the paper, confirming the 16K context window:
We start base model training with a 4k context window and subsequently fine-tune the model with a 16k context window
And
We further pre-trained each model for long-context on 200B tokens from the same pre-training corpus, using a 16,384 context length with a sliding window of 4,096, with FlashAttention-2
Does the context include both the prompt tokens and prediction tokens? During the evaluation of RepoBench, for instance, they restricted the prompt context so that the prediction had a window of 128 tokens:
We constrained the models to generate a maximum of 128 new tokens per prompt, and the first non-empty and non-comment line of the output was selected as the prediction.
And
The maximum token count for prompts was set to 15,800 by truncating excess cross-file context
I typically use OpenAI’s GPT-3.5 or GPT-4 for generating entire pages of code for languages I don’t know, but for in-line use in VSCode, a couple hundred tokens is plenty.
Using StarCoder2 with ollama from VSCode
Run StarCoder2
In a new terminal tab, run
./ollama-linux-amd64 run starcoder2:15b
(Depending on the amount of VRAM you have, you might need to run 7b or 3b, or pick a quantised version of the model .)
Install the Continue VSCode extension
While the model is downloading, install the Continue VSCode extension. Once installed, click Continue’s gear icon, and in the config.json, add the following snippet to the models section:
{
"title": "StarCoder2 + Ollama",
"provider": "ollama",
"model": "starcoder2:15b",
"completionOptions": {
"temperature": 0.2,
"topP": 0.95,
"topK": 40,
"presencePenalty": null,
"frequencyPenalty": null,
"stop": null,
"maxTokens": 600
}
}
Quick test
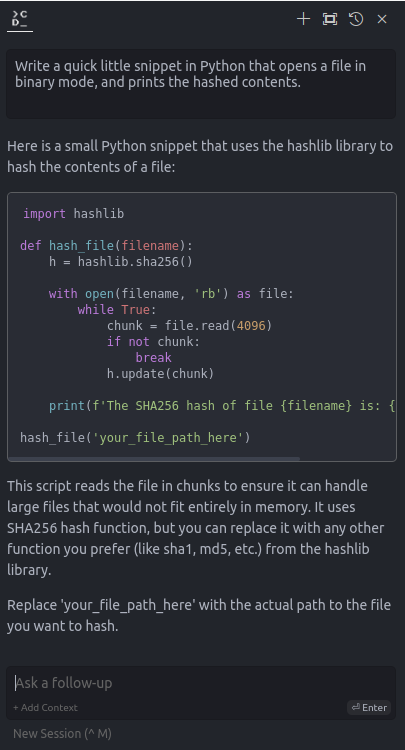
As a quick test, I gave the chat interface the following prompt:
Write a quick little snippet in Python that opens a file in binary mode, and prints the hashed contents.
Continue by default points to GPT-4 (Free Trial), which responded with this bit of code:
import hashlib
def hash_file(filename):
h = hashlib.sha256()
with open(filename, 'rb') as file:
while True:
chunk = file.read(4096)
if not chunk:
break
h.update(chunk)
print(f'The SHA256 hash of file {filename} is: {h.hexdigest()}')
hash_file('your_file_path_here')
Then I switched to the StarCoder2 + Ollama model, and got this response:
import hashlib
with open('file', 'rb') as f:
print(hashlib.sha256(f.read()).hexdigest())
But, in addition to the Python code, it also exhausted it’s output token budget with what looked like a Python tutorial (which is fine - I can ignore that).
The functions output the same hash.
It’s as if StarCoder2 got straight to the point, but GPT-4 went a step further and wrapped it in a function and read the file in chunks, which probably makes for more maintainable and correct code.
However, not bad considering GPT-4 is SOTA, costs a lot more to run, and is (probably) a much larger (ensemble of) model(s). I’m excited to see what else StarCoder2 can do.
What I’m also very interested in is using my own development data to fine-tune StarCoder2 (or any model I choose to use), and it seems as if Continue has support for this (albeit possibly a paid feature?), but over here at PDFCrunch we’re quite confortable fine-tuning our own models anyway.
{kind=link}
Another great thing about Continue is that it indexes your entire codebase, so you can ask the model high-level questions about your codebase, like “Do I use X anywhere?” or “Is there any code written already that does X?”. Powerfull stuff, and I wonder if there are limitations - you might want to index your million-line monolith or mono-repo.
Conclusion
I’ve just dropped $100 on a new year of Github Copilot earlier this week, but I’ll continue using StarCoder2-15b + ollama + Continue for the foreseeable future, and see how it stacks up.
This post was inspired by this video which uses Dolphin Mixtral + LMStudio + Continue instead: